yoguz
yoguz
�鿴yoguz�IJ���

| ��Ǯ | : 18255 |
| Level | : 0 |
| ������ | : 1564 |
| ����½ | : 2019/10/24 |
| ע��ʱ�� | : 2004/12/13 |
|
��վ��ά֮�������ڿ�����
ʲô����վ��ά(Web operations) ����ά��������ijЩ�����а�װϵͳ��������������ô��? ��ȥӦ�ÿ�����ҵ����Ӫ֮��ı�����վ����ת���¶�����������ά������ְ��Χ����ά�Ĺ�������(��������) ��Ӳ���������������Ӧ�ó���ά������ȫ�������滮���������ȵȡ�
��ά���б���"��Ӫ"�������ĵ��ᄈ�У���Ӫ�����ҵ������һ��ġ�����ά������ƫ�������档
�κ�һ���ɹ���վ�㶼�벻��һֻ�������ά�Ŷӣ��������Ǹ���ʱ����������վ����Ϊ��֪��
��վ������
��ν��վ������(availability)Ҳ����վ��������ʱ��İٷֱȣ�����ÿ����Ӫ�Ŷ�����Ҫ�� KPI (Key Performance Indicators ���ؼ�ҵ��ָ��)������ Web վ����˵����ͳ���Ǹ� 24x7 ��˵���Ѿ����Ǻ������ˣ�����ҵ��������� N ��9 �����������ԣ� �˵�ľ������� "4��9(Ҳ����99.99%)" �Ŀ����ԡ���һ�±� 1 �ܸ�Ϊֱ��һЩ��
���� ͨ�з� �����Լ��� ���ͣ��ʱ��
���������� 2��9 99% 87.6Сʱ
�ϸ߿����� 3��9 99.9% 8.8Сʱ
���й����Զ��ָ������Ŀ����� 4��9 99.99% 53����
���߿����� 5��9 99.999% 5����
����ī�ƶ��������ۣ�������û�� 100% �ɿ��� Webվ��(���Dz�����)��ҵ����վ�Ŀ����Զ��Ƕ��٣�����עĿ�� Web �¹� Twitter (http://twitter.com)�� 2008 ��ǰ�ĸ��µĿ�����ֻ�� 98.72%���� 37Сʱ 16���Ӳ����ṩ������2��9 ���ﲻ����������û�ﵽ"��������"״̬�����������ͷ eBay 2007 ��Ŀ������� 99.94%�����ǵ� eBay վ��Ĺ�ģ��Ӧ�õĸ��ӳ̶ȣ����Ǹ��ܲ���������ָ���ˡ�Web Ӧ�����;����˲�ͬ��վ��Կ����Ե��������Dz�ͬ�ġ� Ҫ֪�� 4 �� 9 �Ŀ�����ʵ�����Ǻ���ʵ�ֵ�Ŀ�ꡣ���� 5 ��9 �� Web վ�㣬һ�뿿�ڹ�����һ�������Ҫ����������
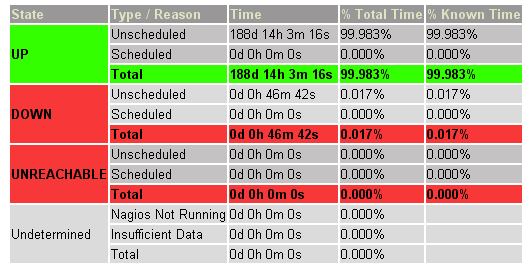
(ͼ1 ά���ٿ���վ��һ̨���ݿ�������Ŀ����������, ��Nagios�ļ�صõ���)
��������£���վ�����Ի��� SLA ��Service Level Agreement, ����ˮƽЭ��) �е�һ����Ҫ����ָ�꣬Ҳ����ά�Ŷ����Լ��Ŀͻ�(�����ǹ�˾�ϰ�)����ʽ��ŵ�����������ܹ������Ľ��Ķ�����KPI �ƶ����в���ʨ�Ӵڣ���ͼһ�����죬�����Դ���һЩ��̫��ʵ��ָ�ꡣ��ά�ŶӶԿ����Եij�ŵҲ���ܿ�Щ��ͷ֧Ʊ����ͷ����ͷ�ѿ���ֵ��ǿ�����ǣ���������������йܣ�����Ҫ��ȷ SLA�����˵������ķ������������Ѿ��˾�ţ����֮�����ڱ�֤����Ӳ������Ȼ��ڶ�û�����ˣ�IDC ȴƵ���ϵ����IDC �������粻���ã���Ҳ����������Ԥ�ڵĸ߿����ԡ�
��߿����Ե�һЩ����������������㣬���������豸(��Ⱥ)�����ô����������ȣ��Կ�����Ҫ�ߵ���վ��Щ�����㹻�ˡ����Ҫ�ṩ���ߵĿ����ԣ����� 4 �� 9 ���� 5 ��9���Ͳ��Ǽ�Ӳ���������������飬����Ҫ�������Ƶ������ƶȡ�����������ơ������¹���Ӧ�ٶȵȡ�����ν��"û����߿��ã�ֻ�и��߿�����"��
һ����˵�����е���վ��ά��Ա��������վ�ĸ�����ĸ߿����ԣ����DZ���ע�⣬�����Զ������Ӳ��Ͷ�롢����������ɱ�Ϊ���۵ġ��ɱ��������֮��Ҳ���������õ�ƽ�⣬äĿ��߿������Dz���ȡ�ġ�
(���䣺Twitter �Ŀ����������Ѿ����˺ܴ����������ǿ��Կ����������Բ��Ѳ���һ����վ��ɱ�֣�ֻҪ��Ʒ���û��㹻�Ѻã��㹻��ճ�ȣ��㹻���ɻ�ȱ����ô�����Բ����ǵ�һҪ�����άĿ�ꡣ��Щ��ά��Ա�� Amazon ��ij��ʥ�����ڼ�崻�����ɵ�Ӱ������������Ӱ����ʵû��ô���£������ľ��ÿ��£���ô����ܱ�һЩ����������Աϴ���ˡ�)
|






![[咽炎吃什么药]每天泡2袋,坚持30天,咽炎好如初](http://www.shuyancha.com/images/syc.jpg)